
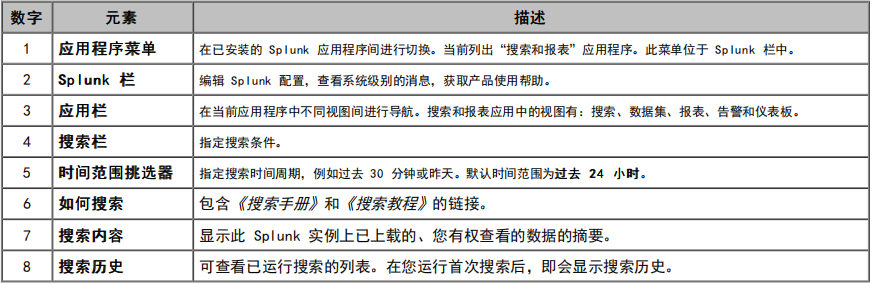
1. 概述
Splunk 是一款强大的机器数据分析平台,被誉为"数据界的谷歌"。它能够对任何机器生成的数据(如日志、性能指标等)进行实时收集、索引、分析和可视化。在安全领域,Splunk 更是安全运营中心(SOC)的核心平台,帮助企业实现安全监控、威胁检测和事件响应。
在很多中、大客户安全建设里,会使用 Splunk 作为 SOC 运营,所以我这里简单记录总结一下,便于后续遇到这个产品能够快速的回顾和上手。
2. 基础架构
直接看架构图,便于我们直观理解。这里不讨论单体架构,在企业场景里,一般都是分布式部署,如下图。
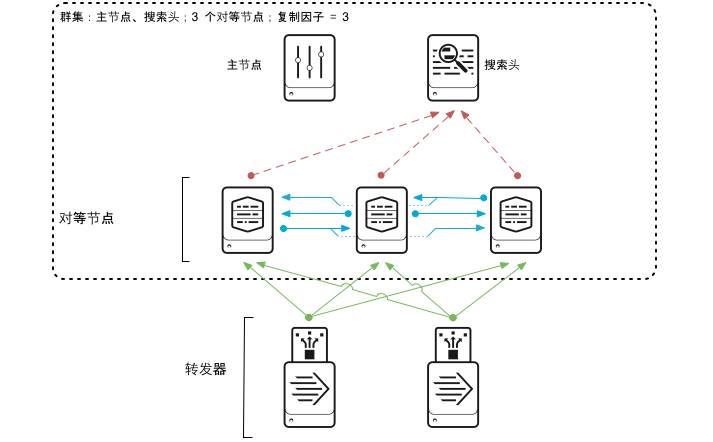
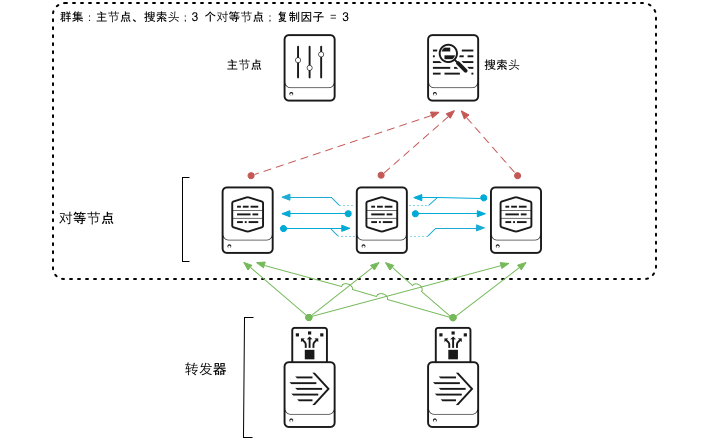
其实主要就包含几部分:
转发器(Forwarder):轻量级数据收集节点,主要作用就是用来接收数据,分为通用、重型、轻型;可以通过本地文件、TCP、UDP、HTTP 等多种方式接收数据。
索引器(Indexer):存储节点,主要作用就是用来存储数据,搜索头的数据集。
搜索头(Search Head):提供用户界面和搜索能力。
其他:简单了解,控制头、授权头等。
实际上,基本每个节点都可以独立使用,只是扮演的角色不同,资源配置不同。比如你可以直接在索引节点上开一个数据接收,直接接收数据,也可以在索引节点上直接进行搜索。
所以,上图就很容易理解了。具体的数据日志如安全设备 WAF 日志、Windows 主机日志、防火墙日志等直接通过 syslog 日志推送或 纯 TCP/UDP 发送到转发器,随后转发器将数据转发到索引器进行存储 ,最后通过搜索头进行数据搜索。
3. 搜索使用
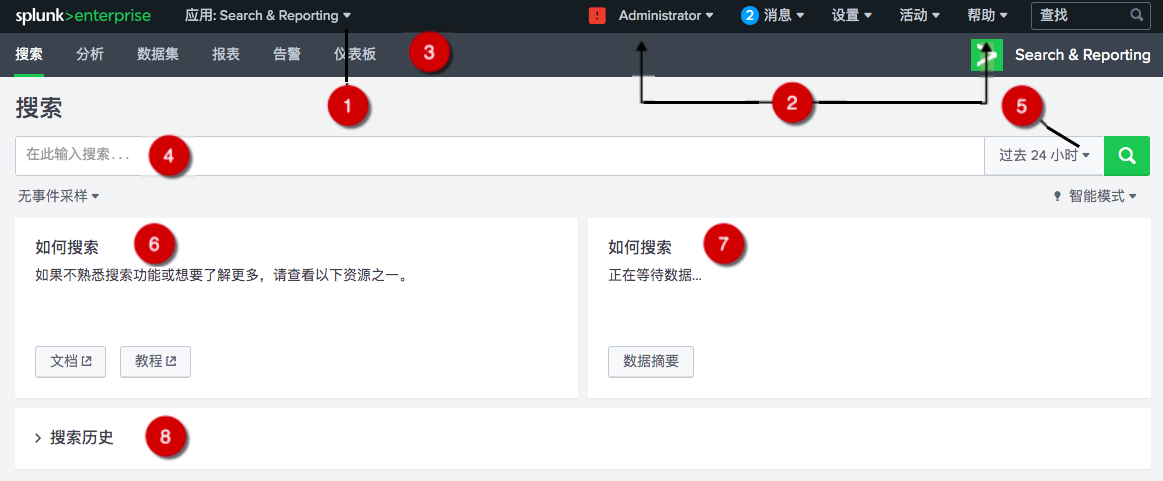
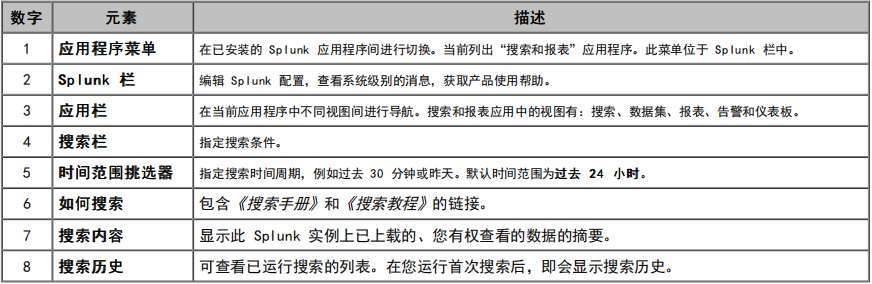
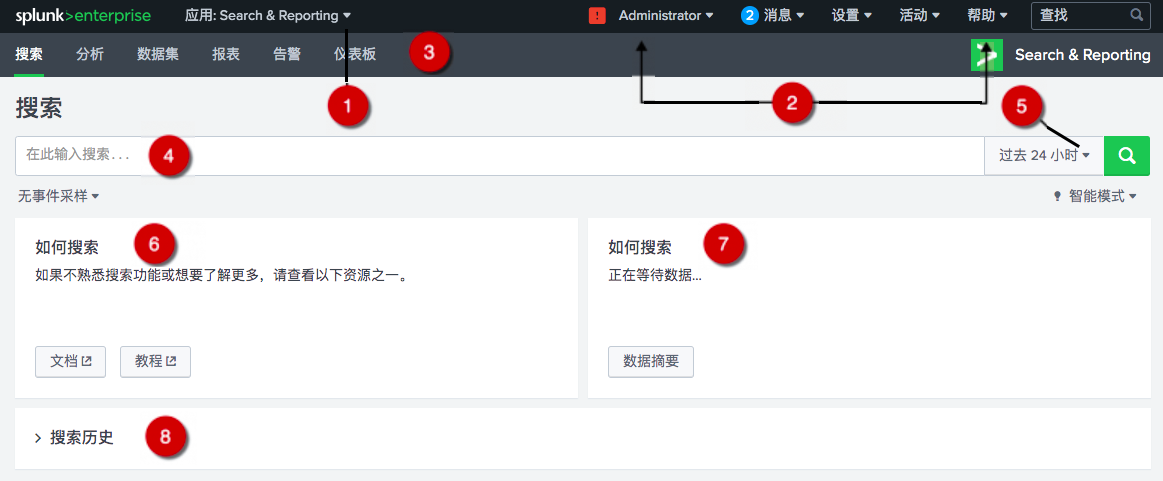
在应急使用场景中,我们最好能够熟练的应用搜索技巧,我简单总结如下:
关键字搜索,可以直接使用通配符*进行搜索,如果存在空格可以使用引号包裹。
运算连接符:AND,NOT、NOT、 管道符 |,注意需要大写。
转义:遇到特殊字符记得转义。
关键语法:stat、table、rename、rex、regex,append 等
在使用前需要,需要提前了解几个主要字段。
index:索引,比如上面创建的 waf_log。
host:主要就是记录是哪个节点发送的日志,比如是安全设备发送过来的,就记录安全设备发送过来的 IP,可以直接锁定设备。
source:数据接入,哪个方式接收的,如上面开放的 TCP:8081。
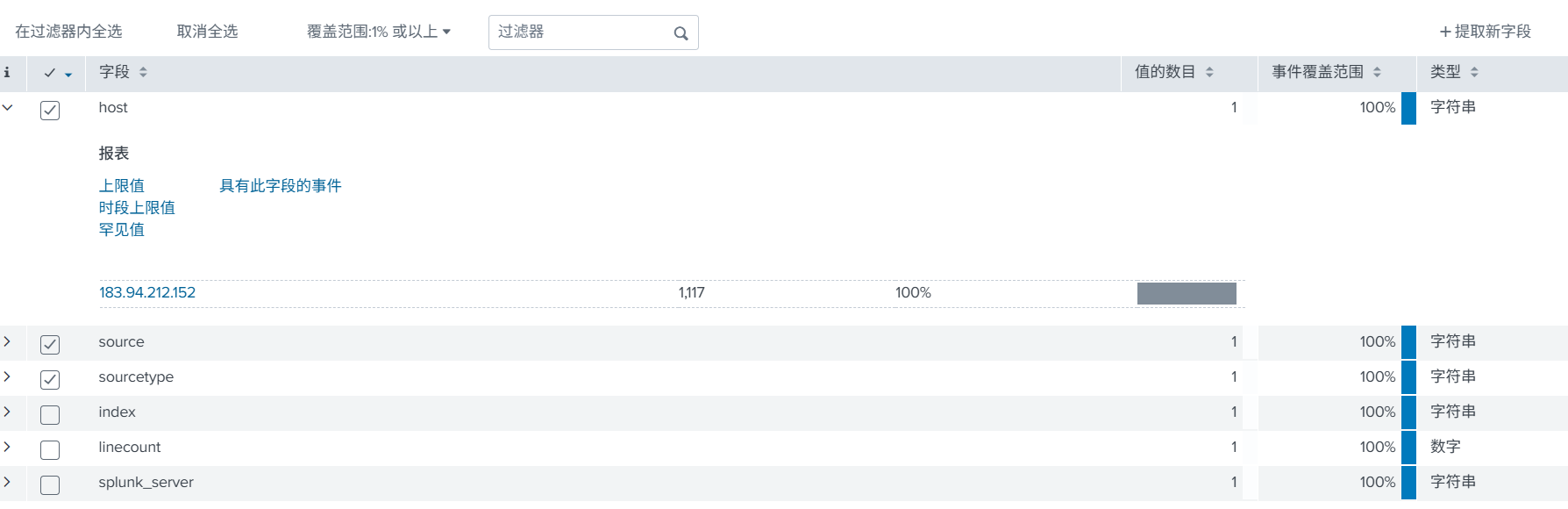
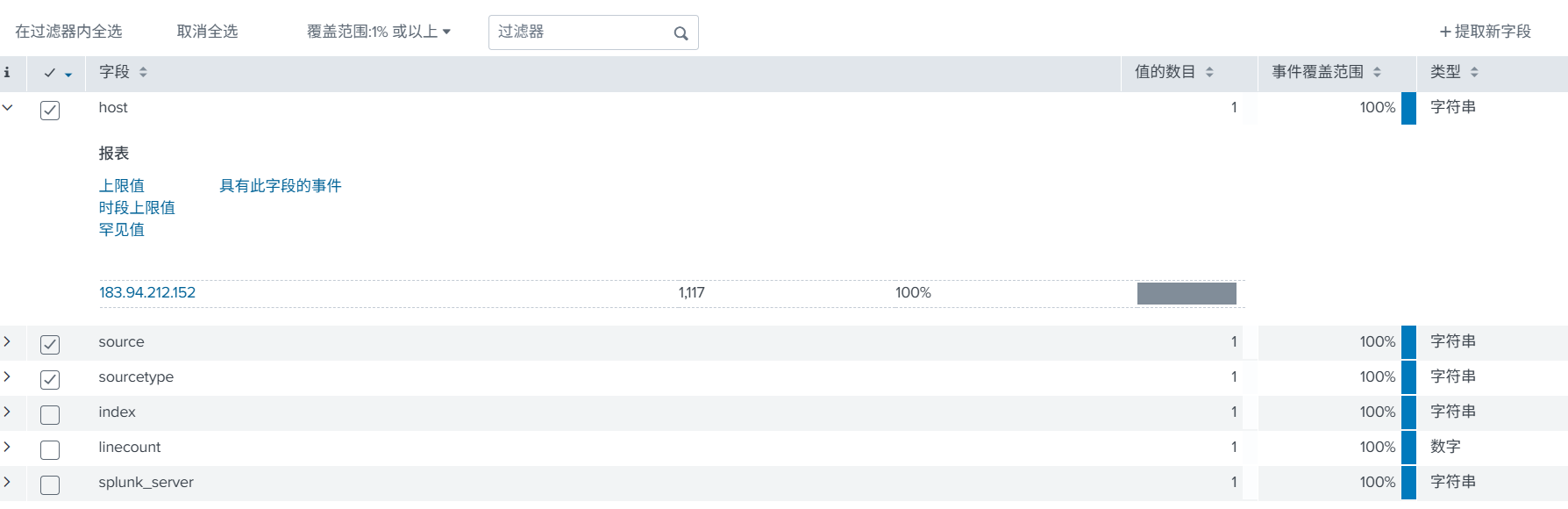
搜索示例:
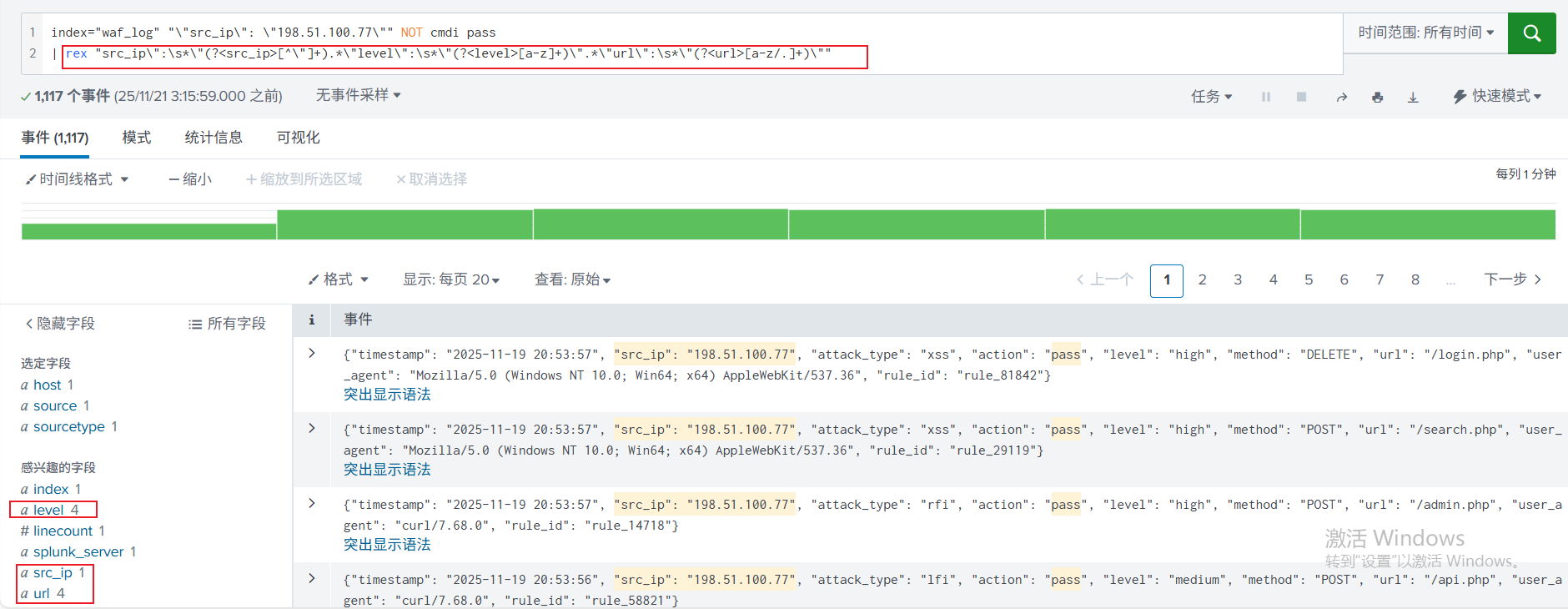
1. 简单关键字搜索,使用了引号和转义。
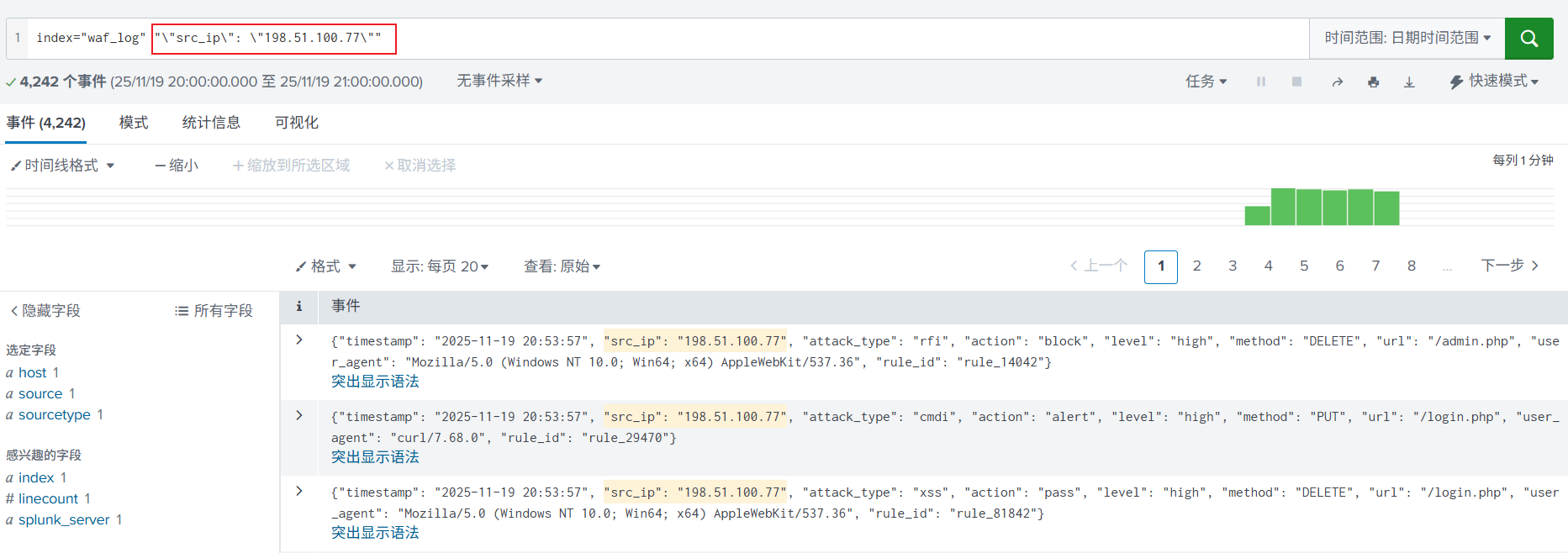
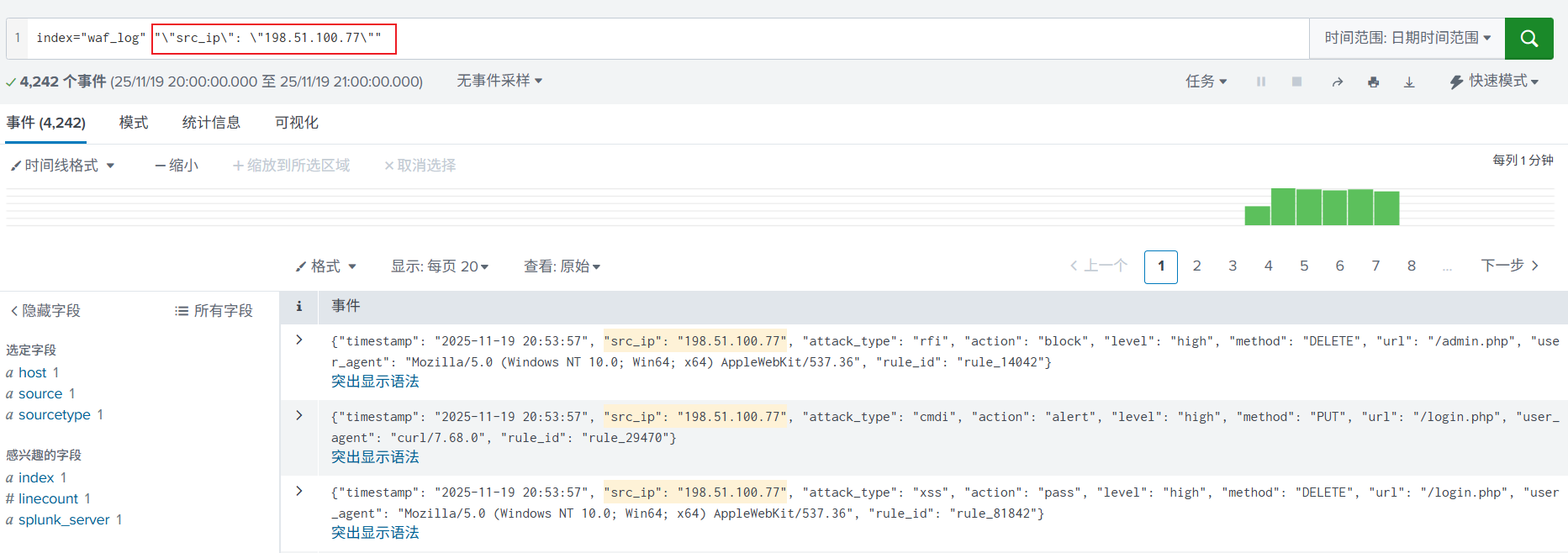
2. 进一步使用运算连接符,加入 NOT、AND(空格)进行搜索,缩小搜索范围。
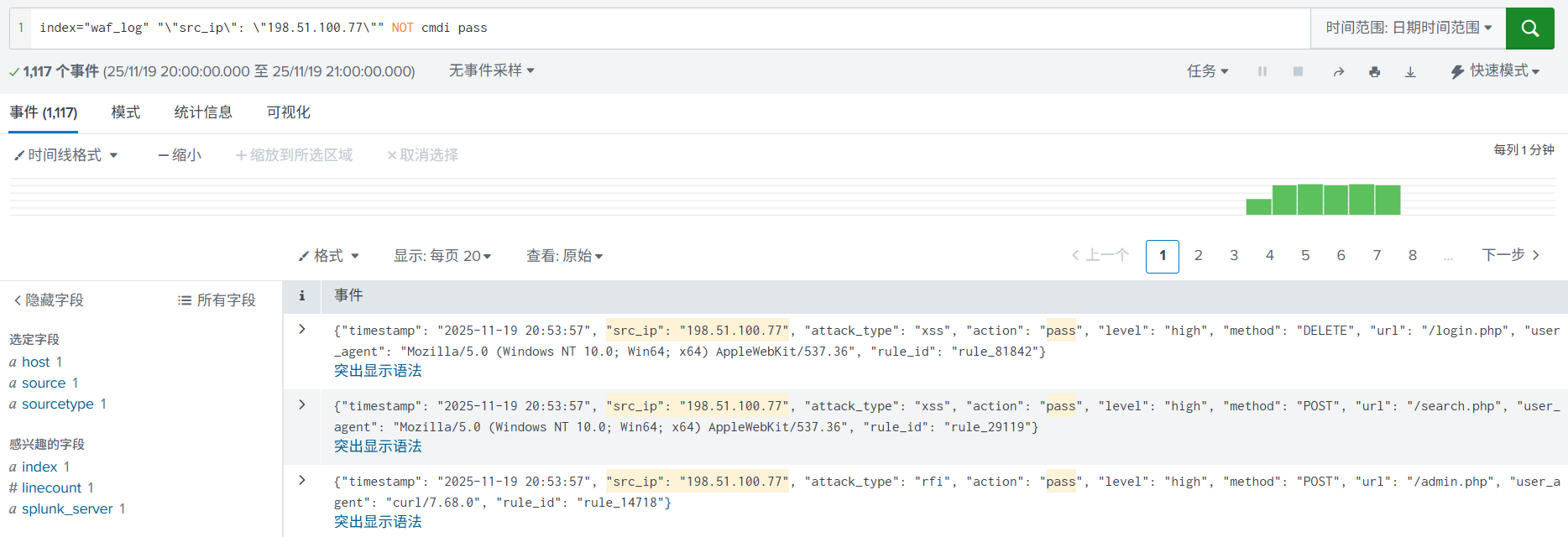
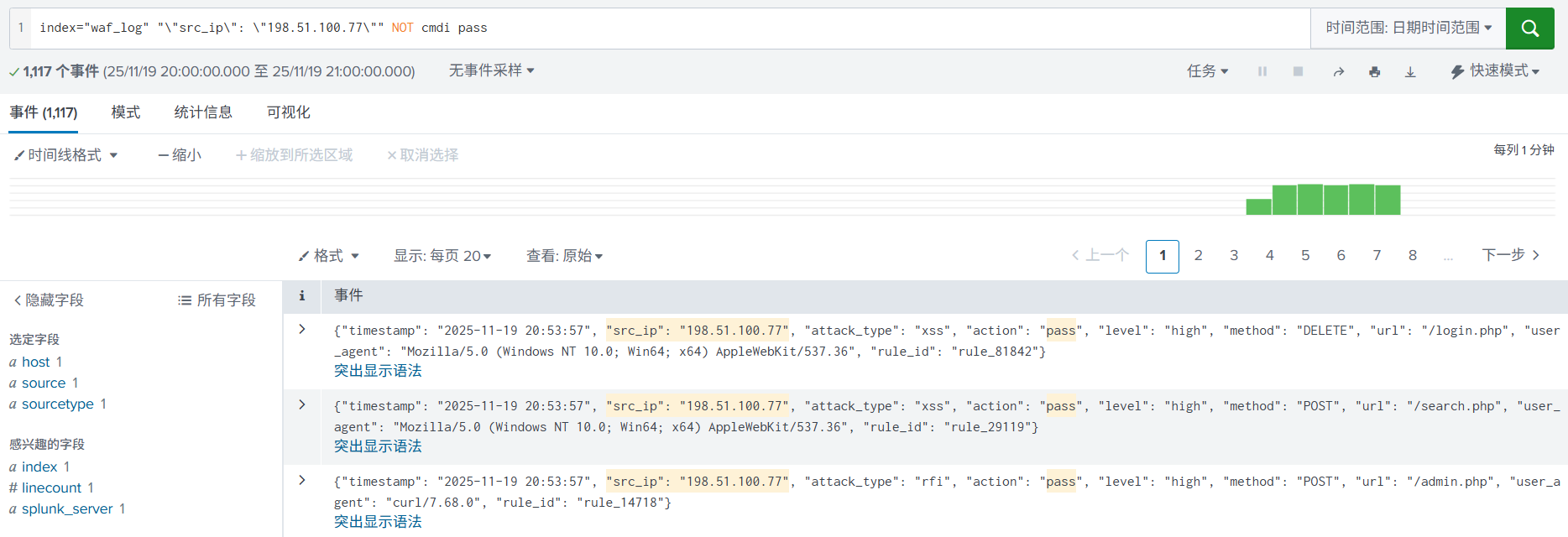
3. 临时提取字段src_ip, level, url,以便用于后续分析。
可能是因为免费版本的原因,导致 json 格式的字段没有直接识别成字段。实际在复杂日志格式时,可以为索引配置字段提取规则进行字段提取,便于直接使用。
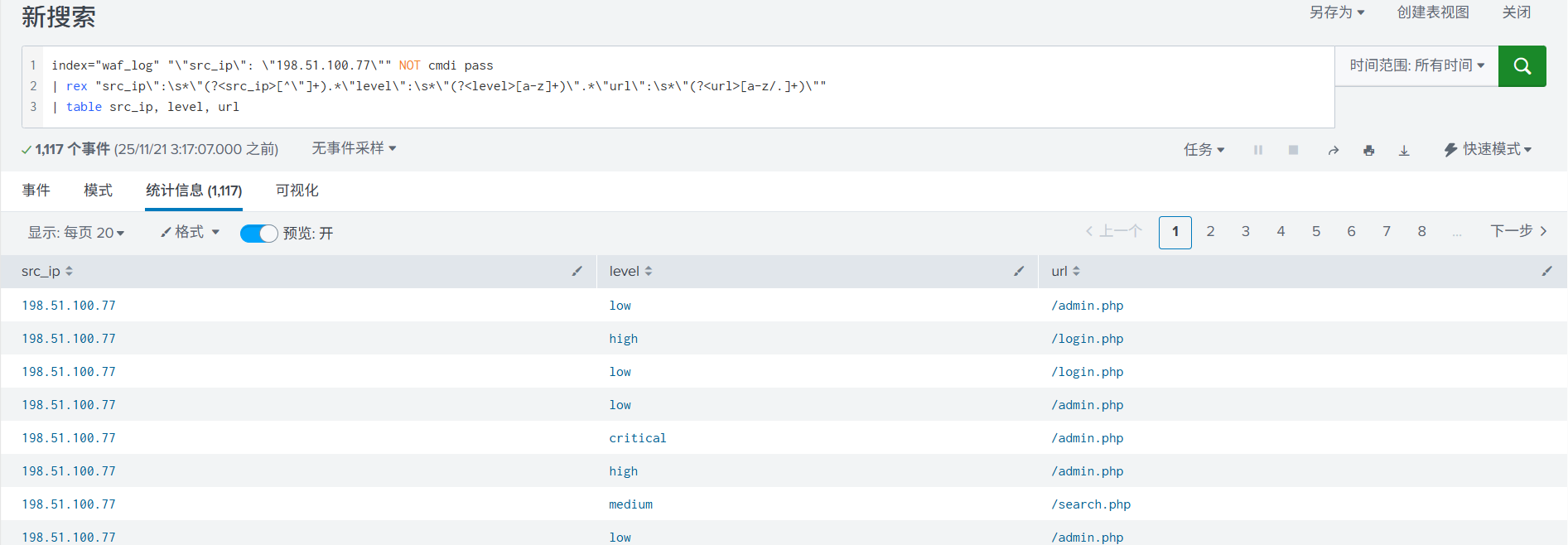
4. 使用统计语法,提取完字段后,直接展示为表格形式,可以更直观的查看。
5. 进一步统计,使用 stats count 根据字段统计出现的次数。
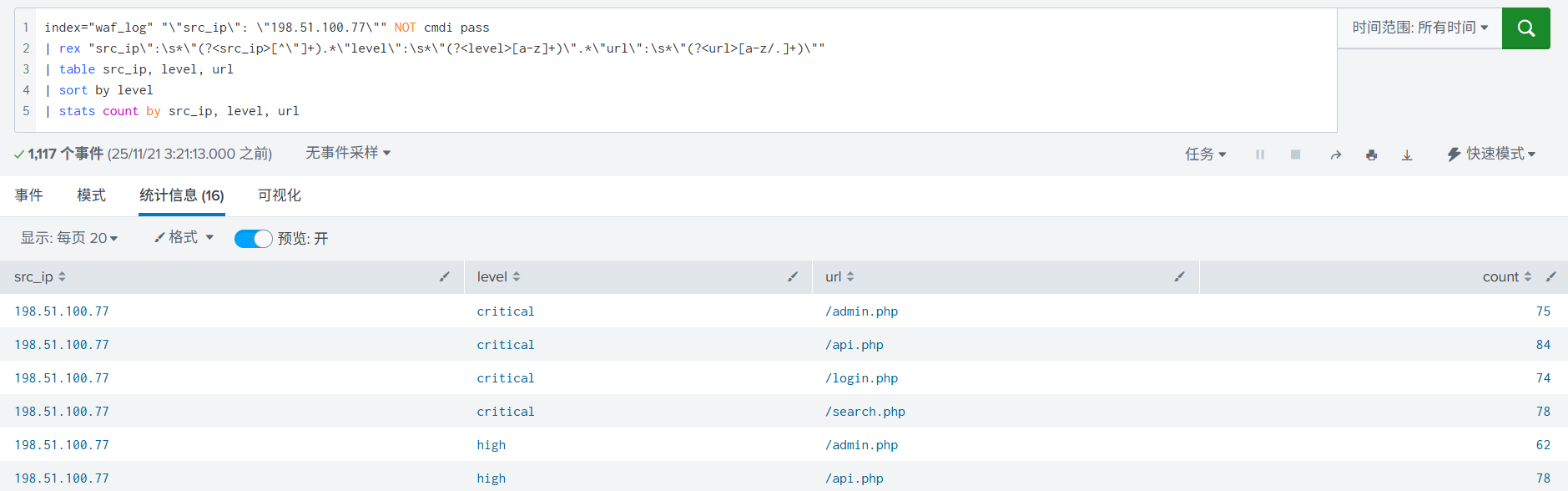
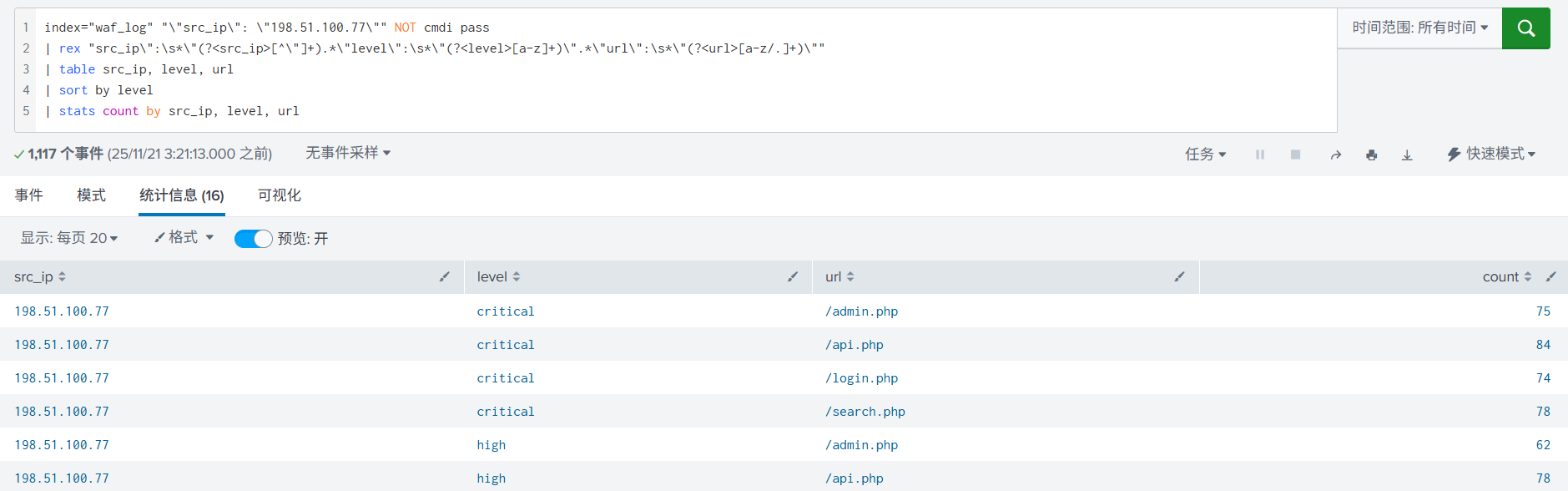
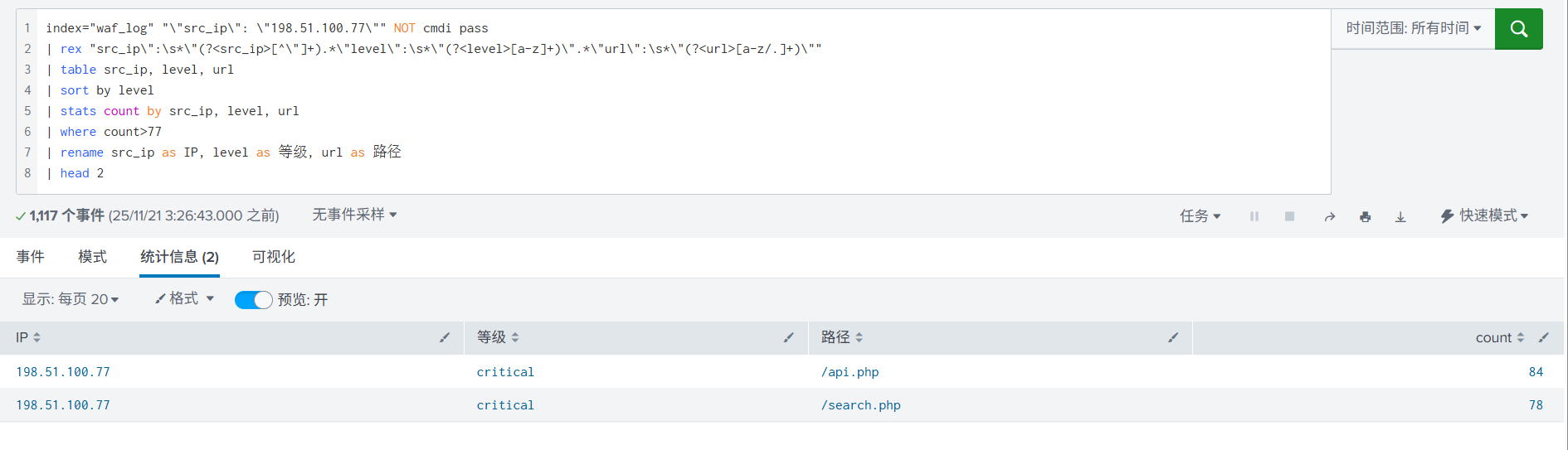
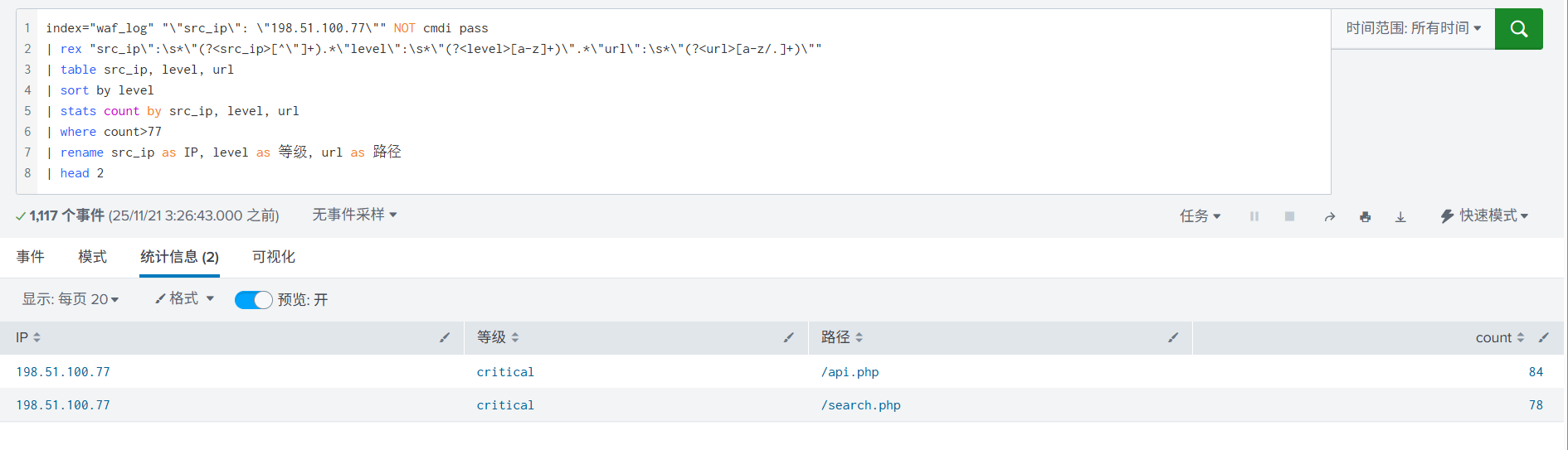
6. 再进一步进行统计, 加入了字段重命名,排序。
4. 其他功能
4.1 告警
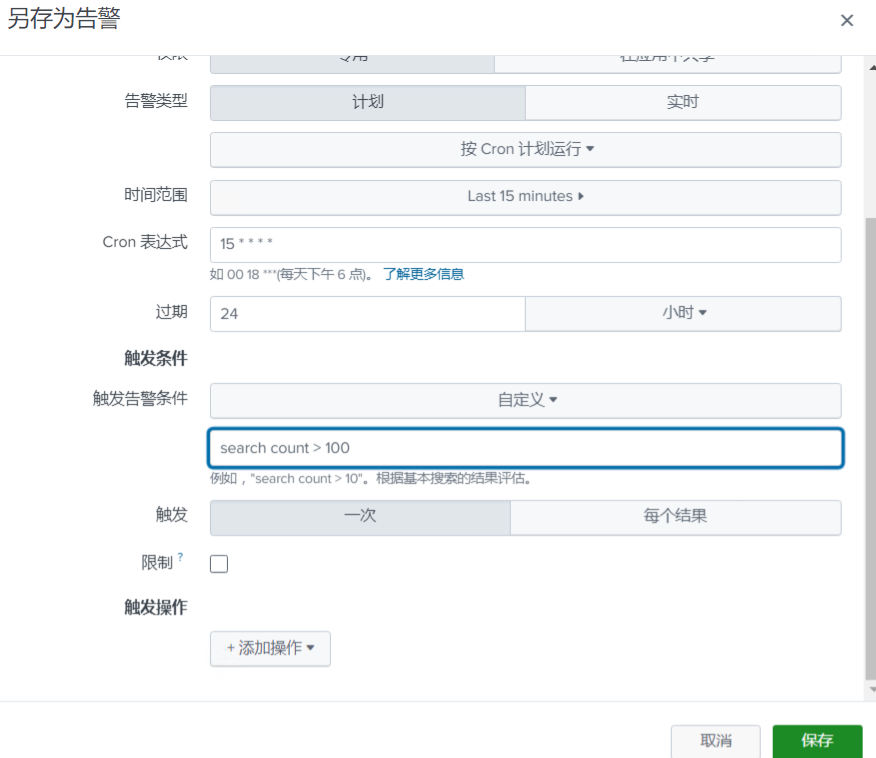
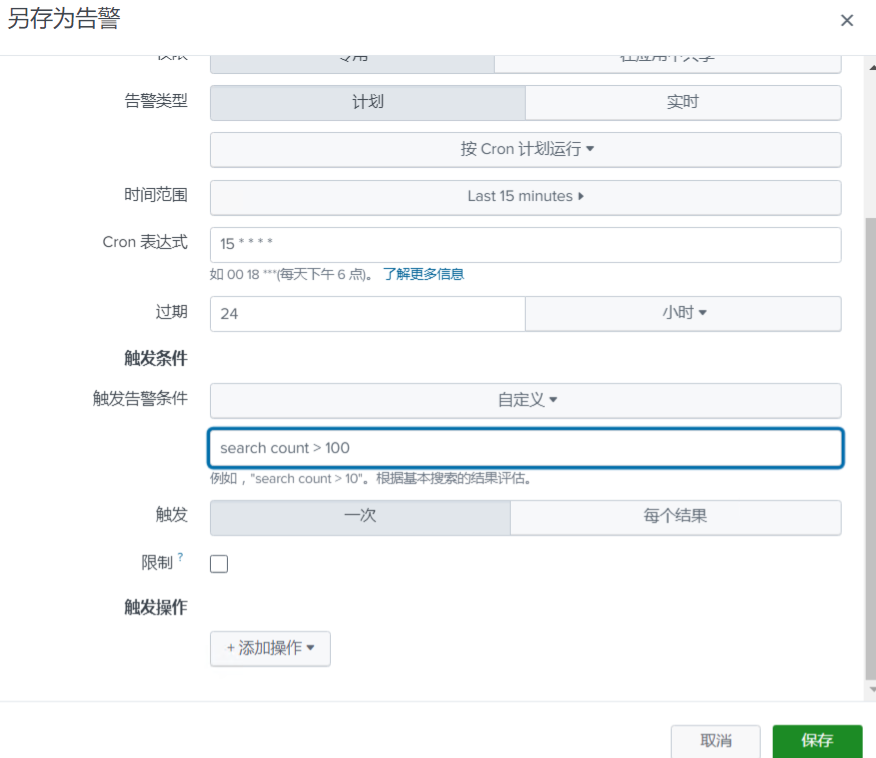
客户运营群里的告警是怎么产生的?其实就是可以设置定时任务进行搜索,就是基于搜索结果筛选关键的字段如table 语法通过电子邮件、webhook 等方式直接进行结果推送输出。
然后通过中间处理程序/服务将结果变成飞书、企微等特殊的消息通知。
4.2 数据输入
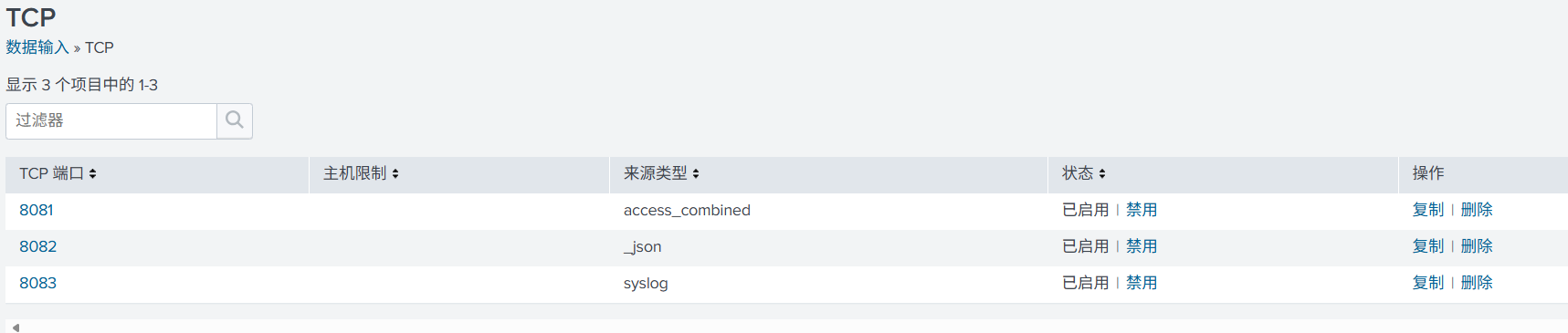
数据输入就是开放端口来接收日志,指定存储的索引及相关配置。以目前数据为例,这边创建了 3 个索引,用于存储数据。
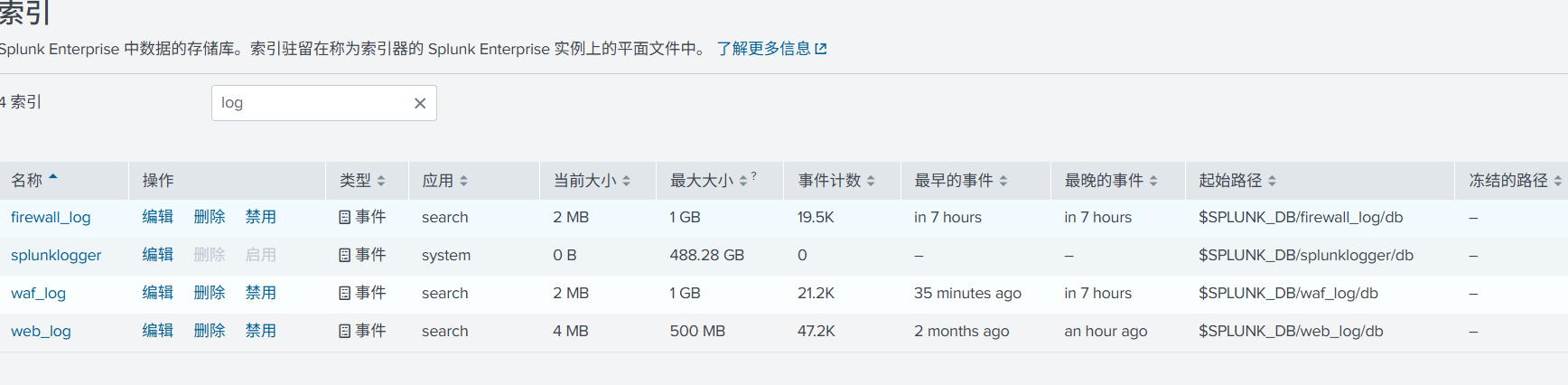
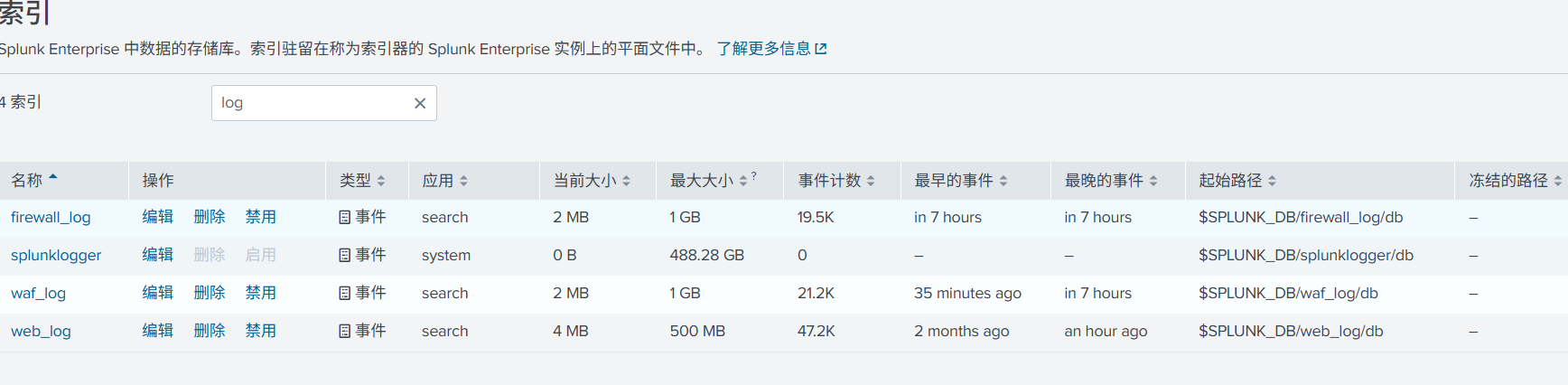
直接创建了 3 个 TCP 端口接收数据输入,分别对应上面的 3 个索引。
5. 总结
实际 Splunk 功能很强大,还有很多功能点未研究,但在应急场景里,只要熟练善用搜索能力即可。因时间有限,后续再进行补充。
附录
附 1-安装使用
docker pull splunk:splunk:latest
docker run -d -p 8000:8000 -p 9997:9997 -e SPLUNK_LICENSE_URI=Free -e "SPLUNK_GENERAL_TERMS=--accept-sgt-current-at-splunk-com" -e "SPLUNK_START_ARGS=--accept-license" -e "SPLUNK_PASSWORD=Wwg@1234" --name splunk splunk:latest附 2-数据生成
这里写了个两个简单脚本生成样例数据便。
模拟安全设备日志脚本,逐行生成 json 格式日志:
import json
import random
import time
import sys
from datetime import datetime
class WAFLogGenerator:
def __init__(self):
# 固定的IP地址池,便于分析
self.fixed_ips = ["192.168.1.100", "10.10.1.50", "172.16.8.123", "203.0.113.45", "198.51.100.77"]
self.attack_types = ["sqli", "xss", "cmdi", "lfi", "rfi", "webshell"]
self.actions = ["block", "alert", "pass"]
self.levels = ["low", "medium", "high", "critical"]
self.methods = ["GET", "POST", "PUT", "DELETE"]
def generate_waf_log(self):
"""生成单条WAF日志(JSON格式)"""
log_entry = {
"timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"src_ip": random.choice(self.fixed_ips),
"attack_type": random.choice(self.attack_types),
"action": random.choice(self.actions),
"level": random.choice(self.levels),
"method": random.choice(self.methods),
"url": f"/{random.choice(['admin', 'api', 'login', 'search'])}.php",
"user_agent": random.choice([
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36",
"python-requests/2.28.1",
"curl/7.68.0"
]),
"rule_id": f"rule_{random.randint(10000, 99999)}"
}
return json.dumps(log_entry, ensure_ascii=False)
def main():
if len(sys.argv) != 2:
print("用法: python waf_generator.py <日志条数>")
sys.exit(1)
try:
num_logs = int(sys.argv[1])
except ValueError:
print("错误: 参数必须是数字")
sys.exit(1)
generator = WAFLogGenerator()
filename = f"waf_logs_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json"
print(f"开始生成 {num_logs} 条WAF日志到文件: {filename}")
with open(filename, 'w', encoding='utf-8') as f:
for i in range(num_logs):
log_line = generator.generate_waf_log()
f.write(log_line + '\n') # 写入文件,每条日志一行
# 在控制台显示进度
if (i + 1) % 10 == 0:
print(f"已生成 {i + 1}/{num_logs} 条日志")
# 添加短暂延迟使时间戳有差异
time.sleep(0.01)
print(f"WAF日志生成完成,共 {num_logs} 条,保存至: {filename}")
if __name__ == "__main__":
main()数据发送脚本,主要功能就是逐行读取文件内容,发送至 Splunk 接收端口:
import socket
import sys
import time
import os
from datetime import datetime
# 目标服务器配置
HOST = '14.103.250.212'
PORT = 8082
if len(sys.argv) < 2:
print("使用方法: python tcp_send.py <日志文件路径>")
print("示例: python tcp_send.py access.log")
sys.exit(1)
log_file = sys.argv[1]
if not os.path.exists(log_file) or not os.path.isfile(log_file):
print(f"✗ 错误: 文件不存在: {log_file}")
sys.exit(1)
print("=" * 60)
print(f"TCP 日志文件发送工具")
print(f"时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
print("=" * 60)
print(f"\n[0/4] 准备读取日志文件...")
print(f" 文件路径: {os.path.abspath(log_file)}")
print(f" 文件大小: {os.path.getsize(log_file):,} 字节")
line_count = 0
with open(log_file, 'r', encoding='utf-8', errors='ignore') as f:
for _ in f:
line_count += 1
print(f" 总行数: {line_count:,} 行")
try:
# 创建socket并连接
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.settimeout(10) # 设置10秒超时
s.connect((HOST, PORT))
local_addr, local_port = s.getsockname()
remote_addr, remote_port = s.getpeername()
print(f" ✓ 连接成功!")
print(f" 本地地址: {local_addr}:{local_port}")
print(f" 远程地址: {remote_addr}:{remote_port}")
total_bytes_sent = 0
success_count = 0
fail_count = 0
with open(log_file, 'r', encoding='utf-8', errors='ignore') as f:
for line_num, line in enumerate(f, 1):
line = line.rstrip('\n\r')
processed_line = line.replace('[', '').replace(']', '')
if not processed_line.strip():
continue
try:
data_to_send = (processed_line + '\n').encode('utf-8')
bytes_sent = s.sendall(data_to_send)
if bytes_sent is None:
total_bytes_sent += len(data_to_send)
success_count += 1
if line_num % 100 == 0 or line_num == line_count:
progress = (line_num / line_count) * 100
print(f" 进度: {line_num}/{line_count} ({progress:.1f}%) - 成功: {success_count}, 失败: {fail_count}")
else:
total_bytes_sent += bytes_sent if bytes_sent else 0
success_count += 1
except Exception as e:
fail_count += 1
print(f" ✗ 第 {line_num} 行发送失败: {e}")
print(f"\n 发送完成!")
print(f" 成功发送: {success_count:,} 行")
if fail_count > 0:
print(f" 发送失败: {fail_count:,} 行")
print(f" 总字节数: {total_bytes_sent:,} 字节")
s.shutdown(socket.SHUT_WR)
time.sleep(0.5)
s.close()
print(f" ✓ 连接已完全关闭")
print("\n" + "=" * 60)
print("✓ 全部操作完成!")
print("=" * 60)
except Exception as e:
print(f"\n✗ 发送失败: {type(e).__name__}: {e}")
sys.exit(1)参考链接: