1.概述
对于经常接触微信小程序渗透的朋友和开发者,应该有所了解,在我们打开加载小程序前,会预先得到一个小程序项目打包编译好的 wxapkg 文件,随后根据用户的反馈来动态加载对应的资源页面;也有可能根据用户的反馈互动来缓存已接收的内容,可以避免频繁请求消耗。前者的可能性更大,当然,两者都只是一个猜测。但是,通过对这个 wxapkg 文件的分析,实际上,确实可以通过该文件还原小程序项目的代码结构,所以,这个猜测或许成立。
wxapkg 在老版本中位于{保存目录}\WeChat Files\Applet,但是目前发现 v4 版本位于C:\Users\{用户名}\AppData\Roaming\Tencent\xwechat\radium\Applet\packages。
在以往的小程序解包反编译过程中, 曾存在需要进行解密操作。在探究时,我的微信已经是 v4 版本,发现生成的 wxapkg 文件基本都是明文状态无需解密,所以猜测可能是客户端加密变化亦或是微信小程序编译有些许变化。
本篇将探究学习wxapkg 的文件结构,并尝试还原解包源代码。
2.文件初探
基于未加密的wxapkg,直接使用二进制阅读器查看没有加密的编译包,如下图:
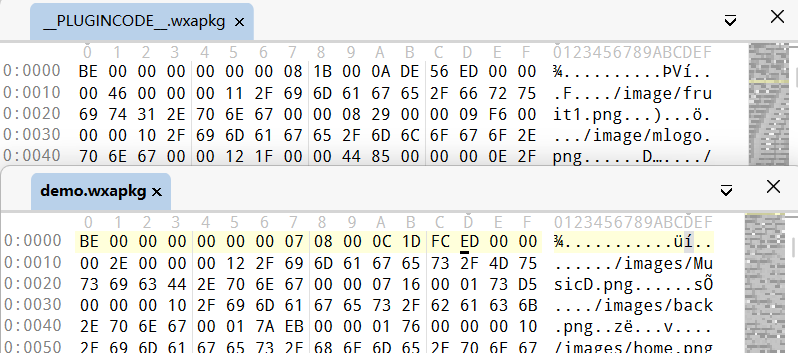
可以看到,文件固定以 BE 00 00 00 开头,存在较明显的项目文件名称,可以初步判断为文件索引区;继续往下翻找,如下,发现明显的代码内容段们可以判断为文件内容,应该为数据区域。
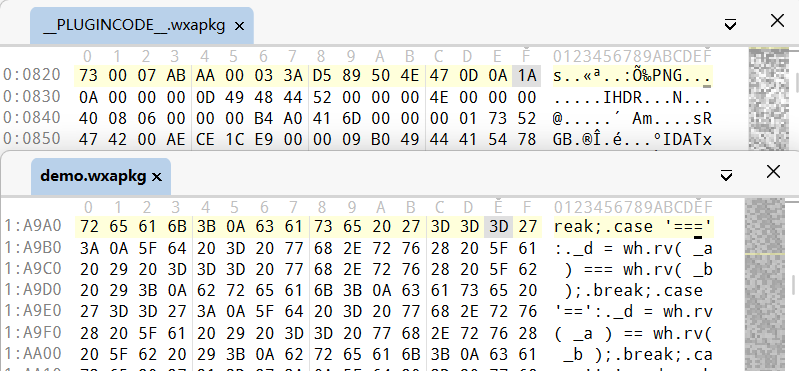
至此,可以展开逐步分析。
3.文件结构
基于互联网大佬们的项目代码以及验证分析,发现文件结构比较简单。主要就包含三部分:文件头、文件索引区、文件数据区。
3.1文件头
主要就包含了文件的模数,标识和内容区段信息。
3.2文件索引区
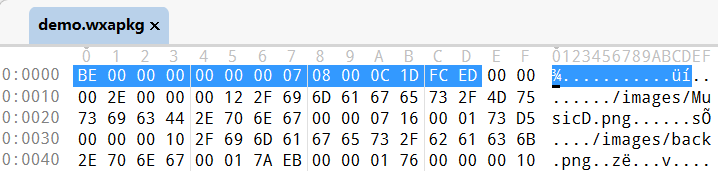
文件索引区主要包含:文件大小 [4 字节] + 文件信息/索引 [ 可算列表,紧邻 ]。每个文件信息索引的结构如下,注意:偏移量是基于 [ 文件大小 ]。
以下面截图为例,可以看到文件名长度为 0x00000012 = 18,蓝色选择部分文件名也可以看出为 18(一行 16 字节),基于文件起始偏移 0x00000716 = 1814个字节的位置为文件内容区域,长度大小为 0x000173D5 = 95189 个字节,所以文件内容区域为 0x00000716~0x00017AEA (0x00000716+0x000173D5)的位置。
3.3文件数据区
这个区域自然没什么可说的,主要用于存储文件内容,每个文件内容紧邻,需要通过已知的内容起始偏移和终止偏移地址来区分每个文件的位置。
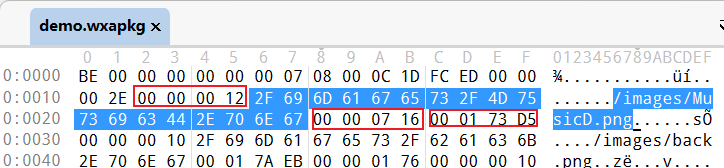
这里验证一下,通过以上文件,我们确定了第一个文件 MusicD.png 的内容起始偏移地址为 0x00000716,定位,如下图,确实找到了文件内容数据,因为89 50 4E 47就是 png 图片的模数。
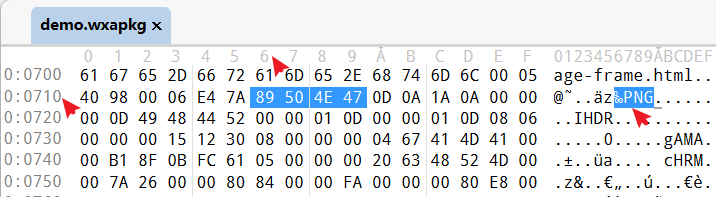
再次确认一下终止位置0x00017AEA,发现后面刚好是下一个 png 图片的起始地址,正好分割开两个文件。
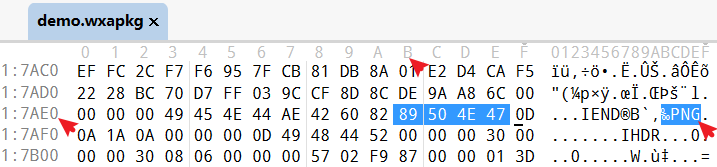
实际也可以将对应字节流保存至文件,可以查看图片是否可以正常打开验证。
4.代码解包
了解了文件的结构,那么还原小程序的项目工程文件的程序编码就比较容易了。
package main
import (
"bytes"
"encoding/binary"
"fmt"
"io"
"os"
"path/filepath"
"strings"
)
// FileHeader 文件头结构
type FileHeader struct {
FirstMark byte // 偏移 0
Info1 uint32 // 偏移 1-4
IndexLength uint32 // 偏移 5-8
BodyLength uint32 // 偏移 9-12
LastMark byte // 偏移 13
}
// FileInfo 文件信息结构
type FileInfo struct {
NameLength uint32 // 文件名长度
Name string // 文件名
Offset uint32 // 文件偏移
Size uint32 // 文件大小
}
// StructureInfo 结构分析结果
type StructureInfo struct {
FilePath string
FileSize int64
Header *FileHeader
FileCount uint32
Files []*FileInfo
IndexStart uint32
DataStart uint32
IndexEnd uint32
DataEnd uint32
AnalysisError error
}
func main() {
fmt.Println("=== 微信小程序文件结构分析工具 ===")
fmt.Println()
// 获取要分析的文件
var files []string
if len(os.Args) > 1 {
files = os.Args[1:]
} else {
// 默认分析当前目录下的wxapkg文件
entries, err := os.ReadDir(".")
if err != nil {
fmt.Printf("❌ 读取目录失败: %v\n", err)
return
}
for _, entry := range entries {
if !entry.IsDir() && strings.HasSuffix(entry.Name(), ".wxapkg") {
files = append(files, entry.Name())
}
}
}
if len(files) == 0 {
fmt.Println("❌ 未找到wxapkg文件")
fmt.Println("使用方法: go run structure-analyzer.go [文件1] [文件2] ...")
return
}
// 分析每个文件
for i, filename := range files {
fmt.Printf("📁 [%d/%d] 分析文件: %s\n", i+1, len(files), filename)
fmt.Println(strings.Repeat("=", 80))
info := analyzeFileStructure(filename)
printStructureInfo(info)
// 询问是否还原文件
if info.AnalysisError == nil && len(info.Files) > 0 {
fmt.Printf("\n❓ 是否还原项目文件? (y/n): ")
var input string
fmt.Scanln(&input)
if strings.ToLower(input) == "y" || strings.ToLower(input) == "yes" {
err := restoreProjectFiles(filename, info)
if err != nil {
fmt.Printf("❌ 还原文件失败: %v\n", err)
} else {
fmt.Printf("✅ 项目文件还原完成!\n")
}
}
}
if i < len(files)-1 {
fmt.Println()
}
}
fmt.Println("\n🎉 分析完成!")
}
func analyzeFileStructure(filename string) *StructureInfo {
info := &StructureInfo{
FilePath: filename,
}
// 读取文件
file, err := os.Open(filename)
if err != nil {
info.AnalysisError = fmt.Errorf("打开文件失败: %v", err)
return info
}
defer file.Close()
// 获取文件信息
fileInfo, err := file.Stat()
if err != nil {
info.AnalysisError = fmt.Errorf("获取文件信息失败: %v", err)
return info
}
info.FileSize = fileInfo.Size()
// 读取文件内容
data := make([]byte, fileInfo.Size())
_, err = file.Read(data)
if err != nil {
info.AnalysisError = fmt.Errorf("读取文件内容失败: %v", err)
return info
}
// 分析文件结构
parseFileStructure(info, data)
return info
}
func parseFileStructure(info *StructureInfo, data []byte) {
if len(data) < 14 {
info.AnalysisError = fmt.Errorf("文件太小,无法分析文件头")
return
}
// 解析文件头
header, err := parseHeader(data)
if err != nil {
info.AnalysisError = fmt.Errorf("解析文件头失败: %v", err)
return
}
info.Header = header
// 验证文件头
if err := validateHeader(header); err != nil {
info.AnalysisError = fmt.Errorf("文件头验证失败: %v", err)
return
}
// 计算各段位置
info.IndexStart = 14
info.DataStart = info.IndexStart + info.Header.IndexLength
info.IndexEnd = info.DataStart
info.DataEnd = uint32(len(data))
// 解析索引段
files, err := parseIndexSection(data, info.IndexStart, info.Header.IndexLength)
if err != nil {
info.AnalysisError = fmt.Errorf("解析索引段失败: %v", err)
return
}
info.Files = files
info.FileCount = uint32(len(files))
}
func parseHeader(data []byte) (*FileHeader, error) {
if len(data) < 14 {
return nil, fmt.Errorf("数据不足,无法解析文件头")
}
header := &FileHeader{}
header.FirstMark = data[0]
header.Info1 = binary.BigEndian.Uint32(data[1:5])
header.IndexLength = binary.BigEndian.Uint32(data[5:9])
header.BodyLength = binary.BigEndian.Uint32(data[9:13])
header.LastMark = data[13]
return header, nil
}
func validateHeader(header *FileHeader) error {
if header.FirstMark != 0xBE {
return fmt.Errorf("无效的文件头标识: 0x%02X (期望: 0xBE)", header.FirstMark)
}
if header.LastMark != 0xED {
return fmt.Errorf("无效的文件尾标识: 0x%02X (期望: 0xED)", header.LastMark)
}
return nil
}
func parseIndexSection(data []byte, start, length uint32) ([]*FileInfo, error) {
if int(start+length) > len(data) {
return nil, fmt.Errorf("索引段超出文件范围")
}
indexData := data[start : start+length]
reader := bytes.NewReader(indexData)
// 读取文件数量
var fileCount uint32
if err := binary.Read(reader, binary.BigEndian, &fileCount); err != nil {
return nil, fmt.Errorf("读取文件数量失败: %v", err)
}
var files []*FileInfo
for i := uint32(0); i < fileCount; i++ {
fileInfo, err := readFileInfo(reader)
if err != nil {
return nil, fmt.Errorf("读取文件信息失败 [%d/%d]: %v", i+1, fileCount, err)
}
files = append(files, fileInfo)
}
return files, nil
}
func readFileInfo(reader *bytes.Reader) (*FileInfo, error) {
var fileInfo FileInfo
// 检查剩余字节数
remaining := reader.Len()
if remaining < 4 {
return nil, fmt.Errorf("剩余字节不足,无法读取文件名长度")
}
// 读取文件名长度
if err := binary.Read(reader, binary.BigEndian, &fileInfo.NameLength); err != nil {
return nil, fmt.Errorf("读取文件名长度失败: %v", err)
}
if fileInfo.NameLength == 0 || fileInfo.NameLength > 1024 {
return nil, fmt.Errorf("文件名长度 %d 不合理", fileInfo.NameLength)
}
// 检查是否有足够字节读取文件名
if reader.Len() < int(fileInfo.NameLength) {
return nil, fmt.Errorf("剩余字节不足,无法读取文件名 (需要 %d 字节,剩余 %d 字节)", fileInfo.NameLength, reader.Len())
}
// 读取文件名
nameBytes := make([]byte, fileInfo.NameLength)
if _, err := io.ReadAtLeast(reader, nameBytes, int(fileInfo.NameLength)); err != nil {
return nil, fmt.Errorf("读取文件名失败: %v", err)
}
fileInfo.Name = string(nameBytes)
// 检查是否有足够字节读取偏移和大小
if reader.Len() < 8 {
return nil, fmt.Errorf("剩余字节不足,无法读取文件偏移和大小 (剩余 %d 字节)", reader.Len())
}
// 读取文件偏移
if err := binary.Read(reader, binary.BigEndian, &fileInfo.Offset); err != nil {
return nil, fmt.Errorf("读取文件偏移失败: %v", err)
}
// 读取文件大小
if err := binary.Read(reader, binary.BigEndian, &fileInfo.Size); err != nil {
return nil, fmt.Errorf("读取文件大小失败: %v", err)
}
return &fileInfo, nil
}
func printStructureInfo(info *StructureInfo) {
// 基础信息
fmt.Printf("📊 基础信息:\n")
fmt.Printf(" 文件路径: %s\n", info.FilePath)
fmt.Printf(" 文件大小: %d 字节 (%.2f KB)\n", info.FileSize, float64(info.FileSize)/1024)
if info.AnalysisError != nil {
fmt.Printf("❌ 分析错误: %v\n", info.AnalysisError)
return
}
// 文件头信息
fmt.Printf("\n📋 文件头结构 (偏移 0-13, 14字节):\n")
fmt.Printf(" 偏移 0: FirstMark = 0x%02X\n", info.Header.FirstMark)
fmt.Printf(" 偏移 1-4: Info1 = 0x%08X (%d)\n", info.Header.Info1, info.Header.Info1)
fmt.Printf(" 偏移 5-8: IndexLength = 0x%08X (%d 字节)\n", info.Header.IndexLength, info.Header.IndexLength)
fmt.Printf(" 偏移 9-12: BodyLength = 0x%08X (%d 字节)\n", info.Header.BodyLength, info.Header.BodyLength)
fmt.Printf(" 偏移 13: LastMark = 0x%02X\n", info.Header.LastMark)
// 段位置信息
fmt.Printf("\n📍 段位置信息:\n")
fmt.Printf(" 文件头: 偏移 0-13 (14 字节)\n")
fmt.Printf(" 索引段: 偏移 %d-%d (%d 字节)\n", info.IndexStart, info.IndexEnd-1, info.Header.IndexLength)
fmt.Printf(" 数据段: 偏移 %d-%d (%d 字节)\n", info.DataStart, info.DataEnd-1, info.Header.BodyLength)
// 文件列表
if len(info.Files) > 0 {
fmt.Printf("\n📄 文件列表 (%d 个文件):\n", len(info.Files))
for i, file := range info.Files {
if i >= 10 { // 只显示前10个文件
fmt.Printf(" ... 还有 %d 个文件\n", len(info.Files)-10)
break
}
ext := strings.ToLower(filepath.Ext(file.Name))
fileType := getFileType(ext)
fmt.Printf(" [%d] %s (%s, %d 字节, 偏移 %d)\n",
i+1, file.Name, fileType, file.Size, file.Offset)
}
// 显示最后几个文件的详细信息
if len(info.Files) > 10 {
fmt.Printf("\n📋 最后几个文件详情:\n")
start := len(info.Files) - 5
if start < 0 {
start = 0
}
for i := start; i < len(info.Files); i++ {
file := info.Files[i]
ext := strings.ToLower(filepath.Ext(file.Name))
fileType := getFileType(ext)
// 计算实际文件位置
fileStart := info.DataStart + file.Offset
fileEnd := fileStart + file.Size
fmt.Printf(" [%d] %s (%s, %d 字节, 偏移 %d)\n",
i+1, file.Name, fileType, file.Size, file.Offset)
fmt.Printf(" 实际位置: %d-%d (数据段起始: %d, 文件总长度: %d)\n",
fileStart, fileEnd-1, info.DataStart, info.FileSize)
// 检查是否超出范围
if int(fileEnd) > int(info.FileSize) {
fmt.Printf(" ❌ 超出文件范围: %d > %d\n", fileEnd, info.FileSize)
} else {
fmt.Printf(" ✅ 在文件范围内\n")
}
}
}
// 统计信息
fmt.Printf("\n📈 文件类型统计:\n")
stats := calculateFileStats(info.Files)
for fileType, count := range stats {
fmt.Printf(" %s: %d 个文件\n", fileType, count)
}
}
// 十六进制转储
fmt.Printf("\n🔍 文件头十六进制转储:\n")
if info.FileSize >= 32 {
data, _ := os.ReadFile(info.FilePath)
printHexDump(data[:32], 0)
}
}
func getFileType(ext string) string {
switch ext {
case ".js":
return "JavaScript"
case ".json":
return "JSON配置"
case ".wxml":
return "WXML模板"
case ".wxss":
return "WXSS样式"
case ".png", ".jpg", ".jpeg", ".gif":
return "图片文件"
case ".svg":
return "SVG图标"
case ".woff", ".woff2", ".ttf", ".eot":
return "字体文件"
case ".mp3", ".wav", ".aac":
return "音频文件"
case ".mp4", ".avi", ".mov":
return "视频文件"
case ".html", ".htm":
return "HTML文件"
default:
return "其他文件"
}
}
func calculateFileStats(files []*FileInfo) map[string]int {
stats := make(map[string]int)
for _, file := range files {
ext := strings.ToLower(filepath.Ext(file.Name))
fileType := getFileType(ext)
stats[fileType]++
}
return stats
}
func printHexDump(data []byte, offset int) {
for i := 0; i < len(data); i += 16 {
// 地址
fmt.Printf("%08X: ", offset+i)
// 十六进制
for j := 0; j < 16; j++ {
if i+j < len(data) {
fmt.Printf("%02X ", data[i+j])
} else {
fmt.Printf(" ")
}
if j == 7 {
fmt.Printf(" ")
}
}
// ASCII
fmt.Printf(" |")
for j := 0; j < 16 && i+j < len(data); j++ {
b := data[i+j]
if b >= 32 && b <= 126 {
fmt.Printf("%c", b)
} else {
fmt.Printf(".")
}
}
fmt.Printf("|\n")
}
}
// restoreProjectFiles 还原项目文件
func restoreProjectFiles(filename string, info *StructureInfo) error {
// 创建输出目录
baseName := strings.TrimSuffix(filename, ".wxapkg")
outputDir := baseName + "_restored"
if err := os.MkdirAll(outputDir, 0755); err != nil {
return fmt.Errorf("创建输出目录失败: %v", err)
}
// 读取原始文件数据
data, err := os.ReadFile(filename)
if err != nil {
return fmt.Errorf("读取原始文件失败: %v", err)
}
fmt.Printf("📂 开始还原到目录: %s\n", outputDir)
fmt.Printf("📊 总共需要还原 %d 个文件\n", len(info.Files))
successCount := 0
errorCount := 0
// 还原每个文件
truncatedCount := 0
for i, file := range info.Files {
err := restoreSingleFile(data, file, info.DataStart, outputDir)
if err != nil {
// 检查是否是截断错误
if strings.Contains(err.Error(), "文件被截断") {
fmt.Printf("⚠️ [%d/%d] 还原成功(截断): %s - %v\n", i+1, len(info.Files), file.Name, err)
successCount++
truncatedCount++
} else {
fmt.Printf("❌ [%d/%d] 还原失败: %s - %v\n", i+1, len(info.Files), file.Name, err)
errorCount++
}
} else {
fmt.Printf("✅ [%d/%d] 还原成功: %s (%d 字节)\n", i+1, len(info.Files), file.Name, file.Size)
successCount++
}
}
fmt.Printf("\n📈 还原统计:\n")
fmt.Printf(" 成功: %d 个文件\n", successCount)
if truncatedCount > 0 {
fmt.Printf(" 其中截断: %d 个文件\n", truncatedCount)
}
fmt.Printf(" 失败: %d 个文件\n", errorCount)
fmt.Printf(" 总计: %d 个文件\n", len(info.Files))
if truncatedCount > 0 {
fmt.Printf("\n⚠️ 注意: 有 %d 个文件因超出数据范围被截断保存\n", truncatedCount)
}
if errorCount > 0 {
return fmt.Errorf("有 %d 个文件还原失败", errorCount)
}
return nil
}
// restoreSingleFile 还原单个文件
func restoreSingleFile(data []byte, file *FileInfo, dataStart uint32, outputDir string) error {
// 计算文件在数据段中的实际位置
fileStart := dataStart + file.Offset
fileEnd := fileStart + file.Size
// 检查文件起始位置
if int(fileStart) >= len(data) {
return fmt.Errorf("文件起始位置超出数据范围 (起始位置: %d, 文件长度: %d)", fileStart, len(data))
}
// 处理文件内容 - 如果超出范围则截断
var fileContent []byte
var truncated bool
var actualSize uint32
if int(fileEnd) > len(data) {
// 文件超出范围,截断到实际数据范围
fileContent = data[fileStart:]
actualSize = uint32(len(data) - int(fileStart))
truncated = true
} else {
// 文件在范围内,正常提取
fileContent = data[fileStart:fileEnd]
actualSize = file.Size
truncated = false
}
// 处理文件路径
filePath := file.Name
if strings.HasPrefix(filePath, "/") {
filePath = filePath[1:] // 移除开头的斜杠
}
// 创建完整的输出路径
fullPath := filepath.Join(outputDir, filePath)
// 创建目录
dir := filepath.Dir(fullPath)
if err := os.MkdirAll(dir, 0755); err != nil {
return fmt.Errorf("创建目录失败: %v", err)
}
// 写入文件
if err := os.WriteFile(fullPath, fileContent, 0644); err != nil {
return fmt.Errorf("写入文件失败: %v", err)
}
// 如果文件被截断,返回特殊错误信息(用于提示)
if truncated {
return fmt.Errorf("文件被截断: 原始大小 %d 字节, 实际保存 %d 字节 (超出数据范围 %d 字节)",
file.Size, actualSize, file.Size-actualSize)
}
return nil
}
输出如:
=== 微信小程序文件结构分析工具 ===
📁 [1/1] 分析文件: .\demo.wxapkg
================================================================================
📊 基础信息:
文件路径: .\demo.wxapkg
文件大小: 795922 字节 (777.27 KB)
📋 文件头结构 (偏移 0-13, 14字节):
偏移 0: FirstMark = 0xBE
偏移 1-4: Info1 = 0x00000000 (0)
偏移 5-8: IndexLength = 0x00000708 (1800 字节)
偏移 9-12: BodyLength = 0x000C1DFC (794108 字节)
偏移 13: LastMark = 0xED
📍 段位置信息:
文件头: 偏移 0-13 (14 字节)
索引段: 偏移 14-1813 (1800 字节)
数据段: 偏移 1814-795921 (794108 字节)
📄 文件列表 (46 个文件):
[1] /images/MusicD.png (图片文件, 95189 字节, 偏移 1814)
[2] /images/back.png (图片文件, 374 字节, 偏移 97003)
[3] /images/home.png (图片文件, 650 字节, 偏移 97377)
[4] /images/play.svg (SVG图标, 755 字节, 偏移 98027)
[5] /images/search.png (图片文件, 831 字节, 偏移 98782)
[6] /images/stop.svg (SVG图标, 751 字节, 偏移 99613)
[7] /app-config.json (JSON配置, 1710 字节, 偏移 100364)
[8] /ColorUI/components/cu-custom.json (JSON配置, 39 字节, 偏移 102074)
[9] /components/LGNavBar/LGNavBar.json (JSON配置, 39 字节, 偏移 102113)
[10] /components/cTplOne/cTplOne.json (JSON配置, 39 字节, 偏移 102152)
... 还有 36 个文件
📋 最后几个文件详情:
[42] /pages/little/index.html (HTML文件, 459 字节, 偏移 338560)
实际位置: 340374-340832 (数据段起始: 1814, 文件总长度: 795922)
✅ 在文件范围内
[43] /pages/loveImg/index.html (HTML文件, 461 字节, 偏移 339019)
实际位置: 340833-341293 (数据段起始: 1814, 文件总长度: 795922)
✅ 在文件范围内
[44] /pages/wxParse/wxParse.html (HTML文件, 4283 字节, 偏移 339480)
实际位置: 341294-345576 (数据段起始: 1814, 文件总长度: 795922)
✅ 在文件范围内
[45] /pages/xqy/index.html (HTML文件, 453 字节, 偏移 343763)
实际位置: 345577-346029 (数据段起始: 1814, 文件总长度: 795922)
✅ 在文件范围内
[46] /page-frame.html (HTML文件, 451706 字节, 偏移 344216)
实际位置: 346030-797735 (数据段起始: 1814, 文件总长度: 795922)
❌ 超出文件范围: 797736 > 795922
📈 文件类型统计:
SVG图标: 2 个文件
JSON配置: 17 个文件
JavaScript: 1 个文件
HTML文件: 22 个文件
图片文件: 4 个文件
🔍 文件头十六进制转储:
00000000: BE 00 00 00 00 00 00 07 08 00 0C 1D FC ED 00 00 |................|
00000010: 00 2E 00 00 00 12 2F 69 6D 61 67 65 73 2F 4D 75 |....../images/Mu|
❓ 是否还原项目文件? (y/n): y
📂 开始还原到目录: .\demo_restored
📊 总共需要还原 46 个文件
✅ [1/46] 还原成功: /images/MusicD.png (95189 字节)
✅ [2/46] 还原成功: /images/back.png (374 字节)
✅ [3/46] 还原成功: /images/home.png (650 字节)
✅ [4/46] 还原成功: /images/play.svg (755 字节)
✅ [5/46] 还原成功: /images/search.png (831 字节)
✅ [6/46] 还原成功: /images/stop.svg (751 字节)
✅ [7/46] 还原成功: /app-config.json (1710 字节)
✅ [8/46] 还原成功: /ColorUI/components/cu-custom.json (39 字节)
✅ [9/46] 还原成功: /components/LGNavBar/LGNavBar.json (39 字节)
✅ [10/46] 还原成功: /components/cTplOne/cTplOne.json (39 字节)
✅ [11/46] 还原成功: /components/cTplThree/cTplThree.json (39 字节)
✅ [12/46] 还原成功: /components/cTplTwo/cTplTwo.json (39 字节)
✅ [13/46] 还原成功: /components/info/info.json (39 字节)
✅ [14/46] 还原成功: /components/loading/loading.json (39 字节)
✅ [15/46] 还原成功: /components/love/love.json (39 字节)
✅ [16/46] 还原成功: /components/navBar/navBar.json (39 字节)
✅ [17/46] 还原成功: /components/navBar/package.json (453 字节)
✅ [18/46] 还原成功: /components/notification/notification.json (39 字节)
✅ [19/46] 还原成功: /custom-tab-bar/index.json (39 字节)
✅ [20/46] 还原成功: /package-lock.json (739 字节)
✅ [21/46] 还原成功: /package.json (243 字节)
✅ [22/46] 还原成功: /pages/components/cardSwiper/cardSwiper.json (39 字节)
✅ [23/46] 还原成功: /project.private.config.json (729 字节)
✅ [24/46] 还原成功: /app-service.js (225835 字节)
✅ [25/46] 还原成功: /ColorUI/components/cu-custom.html (479 字节)
✅ [26/46] 还原成功: /components/LGNavBar/LGNavBar.html (479 字节)
✅ [27/46] 还原成功: /components/cTplOne/cTplOne.html (475 字节)
✅ [28/46] 还原成功: /components/cTplThree/cTplThree.html (483 字节)
✅ [29/46] 还原成功: /components/cTplTwo/cTplTwo.html (475 字节)
✅ [30/46] 还原成功: /components/info/info.html (463 字节)
✅ [31/46] 还原成功: /components/loading/loading.html (475 字节)
✅ [32/46] 还原成功: /components/love/love.html (463 字节)
✅ [33/46] 还原成功: /components/navBar/navBar.html (471 字节)
✅ [34/46] 还原成功: /components/notification/notification.html (495 字节)
✅ [35/46] 还原成功: /custom-tab-bar/index.html (463 字节)
✅ [36/46] 还原成功: /pages/PhtotList/index.html (465 字节)
✅ [37/46] 还原成功: /pages/components/cardSwiper/cardSwiper.html (499 字节)
✅ [38/46] 还原成功: /pages/detail/detail.html (461 字节)
✅ [39/46] 还原成功: /pages/index/index.html (457 字节)
✅ [40/46] 还原成功: /pages/leaving/index.html (461 字节)
✅ [41/46] 还原成功: /pages/list/index.html (455 字节)
✅ [42/46] 还原成功: /pages/little/index.html (459 字节)
✅ [43/46] 还原成功: /pages/loveImg/index.html (461 字节)
✅ [44/46] 还原成功: /pages/wxParse/wxParse.html (4283 字节)
✅ [45/46] 还原成功: /pages/xqy/index.html (453 字节)
⚠️ [46/46] 还原成功(截断): /page-frame.html - 文件被截断: 原始大小 451706 字节, 实际保存 449892 字节 (超出数据范围 1814 字节)
📈 还原统计:
成功: 46 个文件
其中截断: 1 个文件
失败: 0 个文件
总计: 46 个文件
⚠️ 注意: 有 1 个文件因超出数据范围被截断保存
✅ 项目文件还原完成!
🎉 分析完成!
5.反编译还原
以上解包只是还原了微信小程序编译后的文件,还需要根据app-service.js、page-frame.html等文件对进行反编译及其他处理才能还原实际的原工程代码。
反编译的教程也较多,这里暂不进行补充。
6.结语
目前发现现有解包、反编译小程序的项目已经比较多,考虑的也比较全面。本文基于这些代码项目进行学习,如果有什么描述错误的地方,欢迎指出并一起学习。
参考链接: